Go 并发:
通常程序会被编写为一个 顺序执行 完成一个独立任务的代码(这样容易维护)。
不过也有一些情况下,需要并行执行多个任务 , 会有更大的好处.
比如 Web 服务需要在各自独立的套接字(socket)上 同时接收多个数据请求。
Go 语言里的并发 指的是 能让某个函数独立于其他函数运行的能力
当一个函数创建为 goroutine 时,Go 会将其视为 一个独立的工作单元。
这个单元会被 调度到可用的 逻辑处理器 上执行。Go 语言运行时的 调度器 是一个复杂的软件,能管理被创建的所有goroutine 并为其分配执行时间。
这个调度器在操作系统 之上,将操作系统的线程与语言运行时的逻辑处理器绑定,并在逻辑处理器上运行goroutine。
调度器 在任何给定的时间,都会全面控制哪个goroutine 要在哪个逻辑处理器上运行。
Go 语言的并发同步模型 来自一个叫作 通信顺序进程(Communicating Sequential Processes,CSP)的范型(paradigm)。
CSP 是一种 消息传递模型,通过在goroutine 之间 传递数据来传递消息,而不是对数据进行加锁来实现同步访问。
用于在goroutine 之间同步和传递数据的关键数据类型叫作 通道(channel)。使用通道可以使编写并发程序更容易,也能够让并发程序出错更少。
1 并发与并行
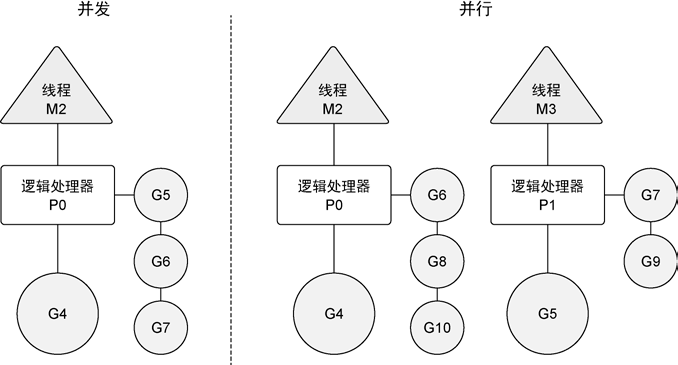
并发(concurrency)不是 并行(parallelism)
并行是让不同的代码片段同时在不同的物理处理器上执行
并行的关键是同时做很多事情,而并发是指同时管理很多事情,这些事情可能只做了一半就被暂停去做别的事情了。
在很多情况下,并发的效果比并行好,因为操作系统和硬件的总资源一般很少,但能支持系统同时做很多事情。
这种“使用较少的资源做更多的事情”的哲学,也是指导Go 语言设计的哲学
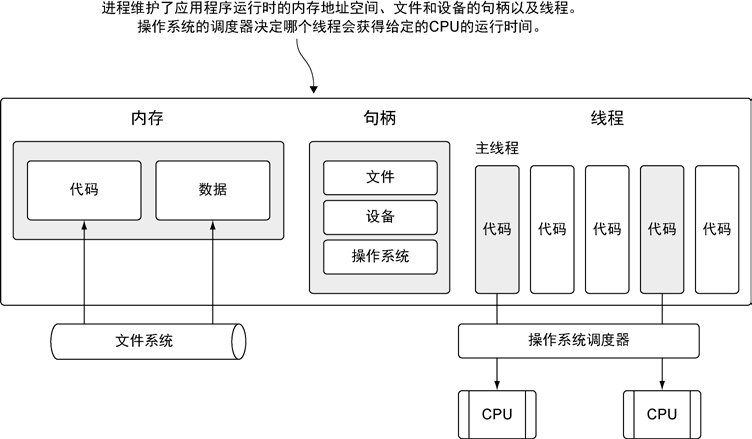
当运行一个应用程序(如一个IDE 或者编辑器)的时候,操作系统会为这个应用程序启动一个 进程。可以将这个进程看作一个包含了应用程序在运行中 需要用到和维护的各种资源 的容器。
这些资源包括但不限于 内存地址空间、文件和设备的句柄以及 线程 …
一个 线程 是 一个执行空间, 这个空间会 被操作系统 调度 ( 调度到某一个CPU处理器上,不一定和进程在一个处理器上 ) 来运行函数中所写的代码
一个运行的应用程序的 进程 和 线程 的简要描绘:
(1) 调度 goroutine 的 逻辑处理器
操作系统 会在 物理处理器 上调度线程来运行, 而Go 语言的运行时会在 逻辑处理器 上 调度 goroutine 来运行。
每个逻辑处理器 都分别绑定到 单个操作系统线程
在1.5 版本以及以上版本,Go语言的运行时默认会 为每个可用的物理处理器分配一个逻辑处理器。
在1.5 版本之前的版本中,默认给整个应用程序 只分配一个逻辑处理器。
这些逻辑处理器会用于执行所有被创建的 goroutine。即便只有一个逻辑处理器,Go也可以以神奇的效率和性能,并发调度无数个goroutine。
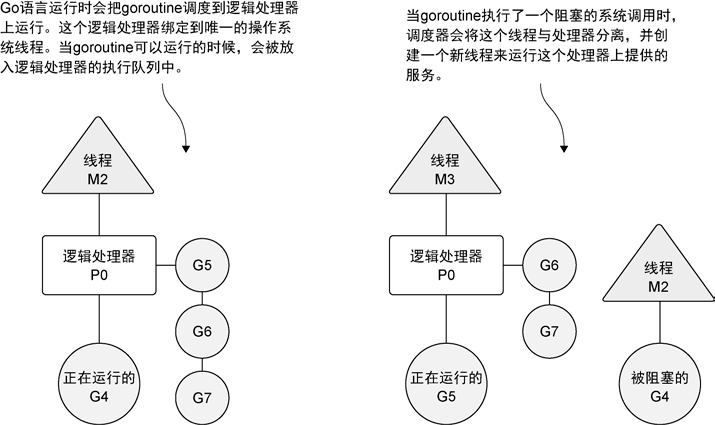
(2) goroutine 并行 (多于一个的逻辑处理器)
当有多个逻辑处理器时,调度器会将goroutine 平等分配到每个逻辑处理器上。这会让goroutine 在不同的线程上运行
并发和并行的区别
2 goroutine
通过关键字go 创建goroutine 来执行
基于调度器的内部算法,一个正运行的goroutine 在工作结束前,可以被停止并重新调度。调度器这样做的目的是 防止某个goroutine 长时间占用逻辑处理器。
当goroutine 占用时间过长时,调度器会停止当前正运行的goroutine,并给其他可运行的goroutine 运行的机会
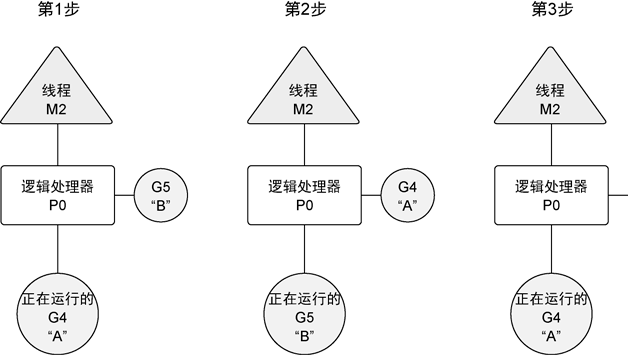
一个逻辑处理器 goroutine并发:
package main
import (
"fmt"
"runtime"
"sync"
)
func main() {
runtime.GOMAXPROCS(1) // 指定调度器可用的逻辑处理器的数量
var wg sync.WaitGroup
wg.Add(2) // 将这个WaitGroup 的值设置为2,表示有两个正在运行的goroutine
fmt.Println("Start Goroutines")
go func() {
defer wg.Done()
for count := 0; count < 3; count++ {
for char := 'a'; char < 'a'+26; char++ {
fmt.Printf("%c", char)
}
}
}()
go func() {
defer wg.Done()
for count := 0; count < 3; count++ {
for char := 'A'; char < 'A'+26; char++ {
fmt.Printf("%c", char)
}
}
}()
fmt.Println("waiting to finish")
wg.Wait()
fmt.Println("\nTerminating Program")
}
结果是 打印 (因为第一个goroutine的任务太过简单,所以很快就完成了,没有涉及到任务的切换)
ABCDEFGHIJKLMNOPQRSTUVWXYZABCDEFGHIJKLMNOPQRSTUVWXYZABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz
多个逻辑处理器 goroutine并行
有多个逻辑处理器且可以同时让每个goroutine 运行在一个可用的物理处理器上的时候,goroutine 才会并行运行
package main
import (
"fmt"
"runtime"
"sync"
)
func main() {
runtime.GOMAXPROCS(2) // 指定调度器可用的逻辑处理器的数量
// 给每个可用的核心分配一个逻辑处理器
// runtime.GOMAXPROCS(runtime.NumCPU())
var wg sync.WaitGroup
wg.Add(2)
fmt.Println("Start Goroutines")
go func() {
defer wg.Done()
for count := 0; count < 3; count++ {
for char := 'a'; char < 'a'+26; char++ {
fmt.Printf("%c", char)
}
}
}()
go func() {
defer wg.Done()
for count := 0; count < 3; count++ {
for char := 'A'; char < 'A'+26; char++ {
fmt.Printf("%c", char)
}
}
}()
fmt.Println("waiting to finish")
wg.Wait()
fmt.Println("\nTerminating Program")
}
结果是打印 (两个任务并行执行 ,结果是没有顺序的输出)
abcdefghijklmnopqrstuvwxyzabcdeABCDEFGHIJKLMNOfghPQRijklmnopqrstuvwxyzabcdefghijkSTUlmnopqrsVWXYZABCDEFGHIJKLMNOPtuvwxyzQRSTUVWXYZABCDEFGHIJKLMNOPQRSTUVWXYZ
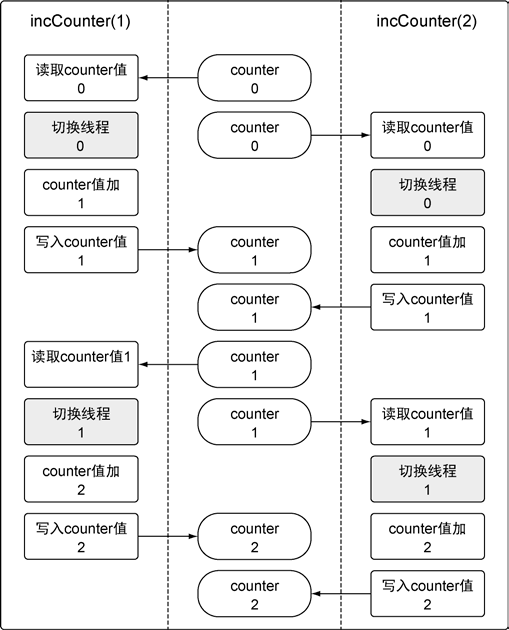
3 共享资源操作的竞争问题
两个或者多个goroutine 在 没有互相同步的情况下,访问某个共享的资源并试图同时读和写这个资源,就处于相互竞争的状态,这种情况被称作竞争状态。
对一个共享资源的读和写操作必须是 原子化 的,换句话说,同一时刻只能有一个goroutine 对共享资源进行读和写操作。
package main
import (
"fmt"
"runtime"
"sync"
)
var (
counter int
wg sync.WaitGroup
)
func main() {
// 计数加2, 等待两个goroutine
wg.Add(2)
// 创建两个 goroutine
go incCounter(1)
go incCounter(2)
// 等待goroutine 结束
wg.Wait()
fmt.Println("Final Counter:", counter)
}
func incCounter(id int) {
// 在函数退出时调用Done来通知 main 函数,工作已经完成
defer wg.Done()
for count := 0; count < 2; count++ {
value := counter
// 当前 goroutine 从线程退出,并放回到队列
runtime.Gosched()
value++
counter = value
}
}
(1)使用锁 来锁住共享数据(传统的同步机制)
Go 语言提供了 传统的同步 goroutine 的机制,就是对共享资源加锁。
如果需要顺序访问一个整型变量或者一段代码,内置的 atomic 和 sync 包里的函数提供了很好的解决方案
sync/atomic 原子函数
atomic.AddInt64(&counter, 1)
这个函数会同步整型值的加法,方法是强制同一时刻只能有一个goroutine 运行并完成这个加法操作。当goroutine 试图去调用任何原子函数时,这些goroutine 都会自动根据所引用的变量做同步处理。
mutex 互斥锁 ( mutex sync.Mutex)
互斥锁用于在代码上创建一个 临界区,保证同一时间只有一个goroutine 可以执行这个临界区代码
同一时刻只有一个goroutine 可以进入临界区。之后,直到调用Unlock()函数之后,其他goroutine 才能进入临界区
for count := 0; count < 2; count++ {
mutex.Lock()
value := counter
runtime.Gosched() // 当前 goroutine 从线程退出,并放回到队列 强制将当前goroutine 退出当前线程后,调度器会再次分配这个goroutine 继续运行
value++
counter = value
mutex.Unlock()
}
(2)另一种同步资源的方式 通道 channel
-
在Go 语言里,你不仅可以使用 原子函数 和 互斥锁 保证对共享资源的安全访问以及消除竞争状态, 还可以使用 通道
-
通道共享资源 是 通过 发送 和 接收 需要共享的资源,在goroutine 之间做同步。
-
声明通道时,需要指定将要被共享的 数据的类型可以通过通道共享 内置类型、命名类型、结构类型 和 引用类型的值 或者 指针。
创建通道
使用 make 创建通道
// 无缓冲 的整型通道
unbuffered := make(chan int)
// 有缓冲 的字符串通道
buffered := make(chan string, 10) // 有缓冲的通道 第二个参数指定这个通道的缓冲区的大小
向通道发送值
使用操作符 <-
// 有缓冲的字符串通道
buffered := make(chan string, 10)
// 通过通道发送一个字符串
buffered <- "Gopher"
从通道里接收值
// 从通道接收一个字符串
value := <-buffered
有无缓冲的通道的差异
无缓冲的通道
接收前 没有能力保存任何值的通道
要求发送goroutine 和接收goroutine 同时准备好,才能完成发送和接收操作
没有同时准备好,通道会导致先执行发送或接收操作的goroutine 阻塞等
使用无缓冲的通道在 goroutine 之间同步

有缓冲的通道
被接收前 能存储一个 或者 多个值的通道
只有在通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞
使用有缓冲的通道在 goroutine 之间同步数据

go 并发小结
并发是指goroutine 运行的时候是相互独立的。
使用关键字go 创建goroutine 来运行函数。
goroutine 在 逻辑处理器上执行,而逻辑处理器具有独立的系统线程和运行队列。
竞争状态是指两个或者多个goroutine 试图访问同一个资源。
原子函数和互斥锁提供了一种防止出现竞争状态的办法。
通道 提供了一种在两个goroutine 之间共享数据的简单方法。
无缓冲的通道保证 同时交换数据,而 有缓冲的通道不做这种保证。
