定义一个操作算法中的框架,而将这些步骤延迟加载到子类中,本质就是固定算法框架
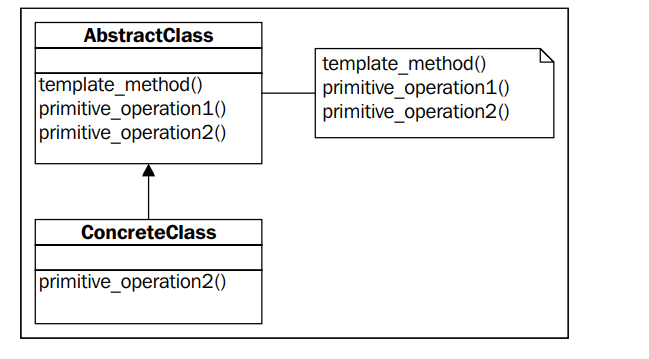
例子
1. Get a URL to make a request to the feed server.
2. Get the raw content.
3. Parse it.
4. Print it for the end user.
import requests # To make http requests to RSS and Atom feeds
from xml.dom import minidom
import os
os.environ['https_proxy'] = 'http://dmfq-proxy.domob-inc.cn:8118'
class AbstractNewsParser(object):
def __init__(self):
# Prohibit creating class instance
if self.__class__ is AbstractNewsParser:
raise TypeError('abstract class cannot be instantiated')
def print_top_news(self):
"""A Template method. Returns 3 latest news for every news
website."""
url = self.get_url()
raw_content = self.get_raw_content(url)
content = self.parse_content(raw_content)
cropped = self.crop(content)
for item in cropped:
print('Title: ', item['title'])
print('Content: ', item['content'])
print('Link: ', item['link'])
print('Published: ', item['published'])
print('Id: ', item['id'])
def get_url(self):
raise NotImplementedError()
def get_raw_content(self, url):
return requests.get(url).text
def parse_content(self, content):
raise NotImplementedError()
def crop(self, parsed_content, max_items=3):
return parsed_content[:max_items]
class YahooParser(AbstractNewsParser):
def get_url(self):
return 'http://news.yahoo.com/rss/'
def parse_content(self, raw_content):
parsed_content = []
dom = minidom.parseString(raw_content)
for node in dom.getElementsByTagName('item'):
parsed_item = {}
try:
parsed_item['title'] = node.getElementsByTagName('title')[0].childNodes[0].nodeValue
except IndexError:
parsed_item['title'] = None
try:
parsed_item['content'] = node.getElementsByTagName('description')[0].childNodes[0].nodeValue
except IndexError:
parsed_item['content'] = None
try:
parsed_item['link'] = node.getElementsByTagName('link')[0].childNodes[0].nodeValue
except IndexError:
parsed_item['link'] = None
try:
parsed_item['id'] = node.getElementsByTagName('guid')[0].childNodes[0].nodeValue
except IndexError:
parsed_item['id'] = None
try:
parsed_item['published'] = node.getElementsByTagName('pubDate')[0].childNodes[0].nodeValue
except IndexError:
parsed_item['published'] = None
parsed_content.append(parsed_item)
return parsed_content
class GoogleParser(AbstractNewsParser):
def get_url(self):
return 'https://news.google.com/news/feeds?output=atom'
def parse_content(self, raw_content):
parsed_content = []
dom = minidom.parseString(raw_content)
for node in dom.getElementsByTagName('entry'):
parsed_item = {}
try:
parsed_item['title'] = node.getElementsByTagName('title')[0].childNodes[0].nodeValue
except IndexError:
parsed_item['title'] = None
try:
parsed_item['content'] = node.getElementsByTagName('content')[0].childNodes[0].nodeValue
except IndexError:
parsed_item['content'] = None
try:
parsed_item['link'] = node.getElementsByTagName('link')[0].getAttribute('href')
except IndexError:
parsed_item['link'] = None
try:
parsed_item['id'] = node.getElementsByTagName('id')[0].childNodes[0].nodeValue
except IndexError:
parsed_item['id'] = None
try:
parsed_item['published'] = node.getElementsByTagName('updated')[0].childNodes[0].nodeValue
except IndexError:
parsed_item['published'] = None
parsed_content.append(parsed_item)
return parsed_content
if __name__ == '__main__':
google = GoogleParser()
yahoo = YahooParser()
print('Google: \n', google.print_top_news())
print('Yahoo: \n', yahoo.print_top_news())
Title: How I realized the NY Times Kavanaugh story was a train wreck - Fox News
Content: <ol><li><a href="https://www.foxnews.com/media/how-i-realized-the-n-y-times-kavanaugh-story-was-a-train-wreck" target="_blank">How I realized the NY Times Kavanaugh story was a train wreck</a> <font color="#6f6f6f">Fox News</font></li><li><a href="https://www.cnn.com/2019/09/16/media/new-york-times-kavanaugh/index.html" target="_blank">New York Times' botched Kavanaugh story the latest in series of blunders from Opinion section</a> <font color="#6f6f6f">CNN</font></li><li><a href="https://www.youtube.com/watch?v=cjvLg47RcwY" target="_blank">What's the process for impeaching a Supreme Court justice?</a> <font color="#6f6f6f">Washington Post</font></li><li><a href="https://www.nytimes.com/2019/09/16/reader-center/brett-kavanaugh-accusation-yale.html" target="_blank">Answers to Reader Questions on Our Brett Kavanaugh Essay</a> <font color="#6f6f6f">The New York Times</font></li><li><a href="https://www.cbsnews.com/news/could-brett-kavanaugh-be-impeached-heres-what-constitution-says-about-supreme-court-justices/" target="_blank">Brett Kavanaugh impeachment question: Could Supreme Court justice be removed after latest accusation, which he denies?</a> <font color="#6f6f6f">CBS News</font></li><li><strong><a href="https://news.google.com/stories/CAAqOQgKIjNDQklTSURvSmMzUnZjbmt0TXpZd1NoTUtFUWo5eF95Z2pvQU1FUlhoaTBhS01ZWnlLQUFQAQ?oc=5" target="_blank">View full coverage on Google News</a></strong></li></ol>
Link: https://www.foxnews.com/media/how-i-realized-the-n-y-times-kavanaugh-story-was-a-train-wreck
Published: 2019-09-17T07:33:59.000000000Z
Id: https://news.google.com/stories/CAAqOQgKIjNDQklTSURvSmMzUnZjbmt0TXpZd1NoTUtFUWo5eF95Z2pvQU1FUlhoaTBhS01ZWnlLQUFQAQ?oc=5
...
Title: Mexican tycoon arrested when boat kills son in San Francisco Bay - Los Angeles Times
Content: <ol><li><a href="https://www.latimes.com/california/story/2019-09-16/mexican-tycoon-javier-burillo-arrested-boat-kills-son-san-francisco-bay" target="_blank">Mexican tycoon arrested when boat kills son in San Francisco Bay</a> <font color="#6f6f6f">Los Angeles Times</font></li><li><a href="https://www.foxnews.com/us/father-arrested-after-son-dies-in-fatal-fall-from-boat-in-california-waters" target="_blank">Father arrested after son dies in fatal fall from boat in California waters</a> <font color="#6f6f6f">Fox News</font></li><li><a href="https://people.com/crime/dad-arrested-both-sons-thrown-off-boat-killing-11-year-old/" target="_blank">Tycoon Arrested After Both His Sons Are Thrown Off His Boat, Tragically Killing His 11-Year-Old</a> <font color="#6f6f6f">PEOPLE.com</font></li><li><a href="https://www.sfgate.com/news/crime/article/Father-arrested-after-boat-kills-son-in-San-14443736.php" target="_blank">Mexican tycoon arrested when boat kills son by San Francisco</a> <font color="#6f6f6f">SF Gate</font></li><li><a href="https://abc30.com/father-arrested-after-boat-kills-son-near-angel-island/5543148/" target="_blank">Father arrested after boat kills son near Angel Island</a> <font color="#6f6f6f">KFSN-TV</font></li><li><strong><a href="https://news.google.com/stories/CAAqOQgKIjNDQklTSURvSmMzUnZjbmt0TXpZd1NoTUtFUWpJaElpaGpvQU1FZUFlWjJta2NGTVVLQUFQAQ?oc=5" target="_blank">View full coverage on Google News</a></strong></li></ol>
Link: https://www.latimes.com/california/story/2019-09-16/mexican-tycoon-javier-burillo-arrested-boat-kills-son-san-francisco-bay
Published: 2019-09-17T02:05:00.000000000Z
Id: https://news.google.com/stories/CAAqOQgKIjNDQklTSURvSmMzUnZjbmt0TXpZd1NoTUtFUWpJaElpaGpvQU1FZUFlWjJta2NGTVVLQUFQAQ?oc=5
Yahoo:
None
