原文引用 – System Design
Chapter IV 系统设计其他常用技术
地理哈希和四叉树 Geohashing and Quadtrees
Geohashing
Geohashing 是一种地理编码方法,用于将地理坐标(例如纬度和经度)编码为短字母数字字符串。
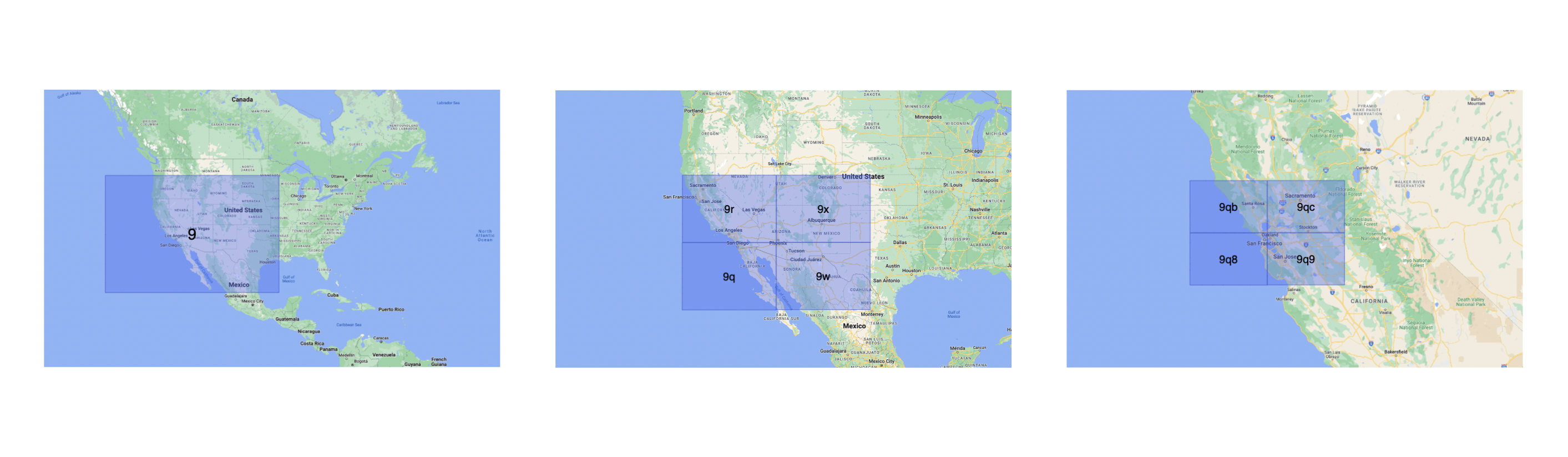
例如,坐标为 37.7564,-122.4016 的旧金山在 geohash 中可以表示为 9q8yy9mf。
- 地理哈希如何工作?
Geohash 是一种使用 Base-32 字母编码的分层空间索引,
geohash 中的第一个字符将初始位置标识为 32 个单元格之一。
该单元格还将包含 32 个单元格。
这意味着为了表示一个点,世界被递归地分成越来越小的单元格,每增加一个位,直到达到所需的精度。 精度因子还决定了单元格的大小。
Geohashing 保证点在空间上更近,如果它们的 Geohashes 共享一个较长的前缀,这意味着字符串中的字符越多,位置越精确。
例如,9q8yy9mf和 9q8yy9vx 在空间上更接近,因为它们共享前缀 9q8yy9。
Geohashing 也可以用来提供一定程度的匿名性,因为我们不需要暴露用户的确切位置,因为根据 geohash 的长度,我们只知道他们在某个区域内的某个地方。
| Geohash length | Cell width | Cell height |
|---|---|---|
1 |
5000 km |
5000 km |
2 |
1250 km |
1250 km |
3 |
156 km |
156 km |
4 |
39.1 km |
19.5 km |
5 |
4.89 km |
4.89 km |
6 |
1.22 km |
0.61 km |
7 |
153 m |
153 m |
8 |
38.2 m |
19.1 m |
9 |
4.77 m |
4.77 m |
10 |
1.19 m |
0.596 m |
11 |
149 mm |
149 mm |
12 |
37.2 mm |
18.6 mm |
-
Geohashing的一些常见用例这是一种在数据库中表示和存储位置的简单方法。
它也可以作为 URL 在社交媒体上共享,因为它比纬度和经度更容易共享和记住。
通过非常简单的字符串比较和高效的索引搜索来高效地找到一个点的最近邻居。
-
例子
Geohashing 被广泛使用,并得到流行数据库的支持。
MySQL
Redis
Amazon DynamoDB
Google Cloud Firestore
Quadtrees四叉树
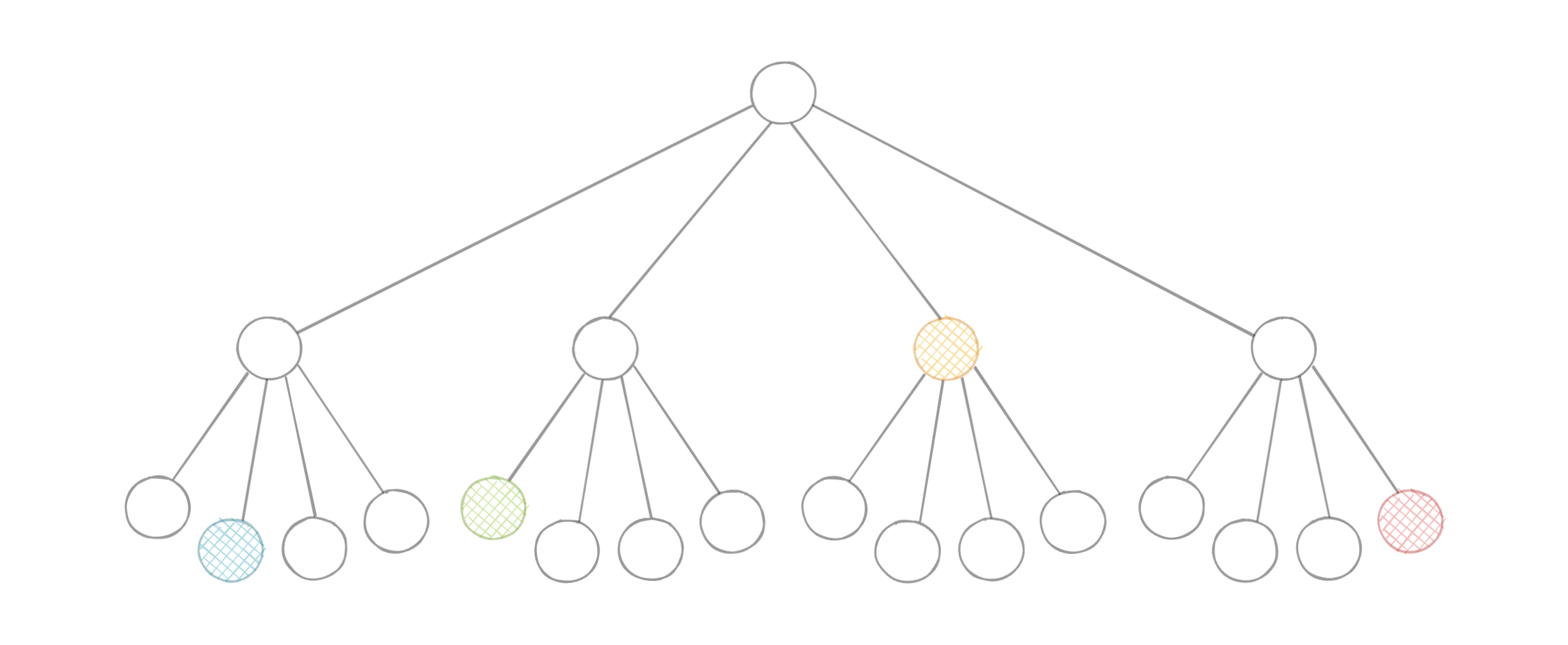
四叉树是一种树数据结构,其中每个内部节点恰好有四个子节点。
它们通常用于通过递归地将二维空间细分为四个象限或区域来划分二维空间。每个子节点或叶节点都存储空间信息。
四叉树是八叉树的二维模拟,用于划分三维空间。
- 四叉树的类型
四叉树可以根据它们表示的数据类型进行分类,包括面、点、线和曲线。
以下是常见的四叉树类型:
Point quadtrees
Point-region (PR) quadtrees
Polygonal map (PM) quadtrees
Compressed quadtrees
Edge quadtrees
- 为什么需要四叉树?
理论上使用纬度和经度我们可以使用欧几里得距离来确定诸如点之间的距离之类的事情,
但对于实际用例来说,它根本无法扩展,因为它具有大型数据集的 CPU 密集型特性。
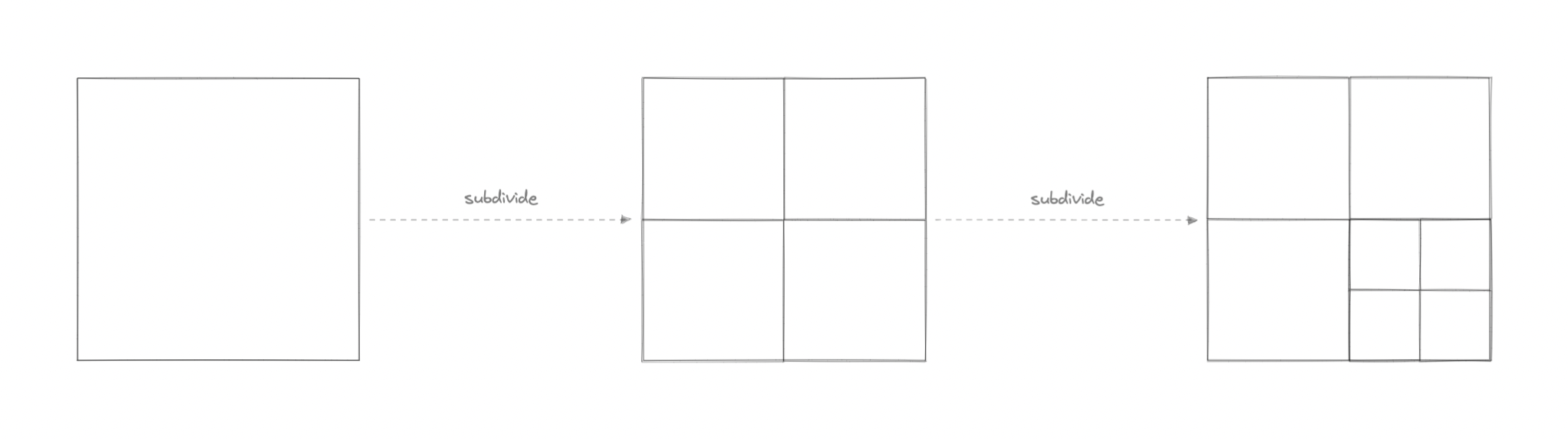
四叉树使我们能够有效地搜索二维范围内的点,其中这些点被定义为纬度/经度坐标或笛卡尔 (x, y) 坐标。
此外,我们可以通过仅在某个阈值之后细分节点来节省进一步的计算。
并且通过Hilbert曲线等映射算法的应用,我们可以轻松提升范围查询的性能。
-
四叉树的一些常见用途:
图像表示、处理和压缩。
空间索引和范围查询。
基于位置的服务,如谷歌地图、优步等。
网格生成和计算机图形学。
稀疏数据存储。
熔断器 Circuit breaker
熔断器是一种用于检测故障的设计模式,封装了防止故障在维护期间不断重复出现、外部系统临时故障或意外系统困难的逻辑。
熔断器背后的基本思想非常简单。
我们将一个受保护的函数调用包装在一个监控故障的断路器对象中。
一旦故障达到某个阈值,断路器就会跳闸,所有对断路器的进一步调用都会返回错误,而根本不会进行受保护的调用。
通常,如果断路器跳闸,我们还需要某种监视器警报。
为什么我们需要熔断?
软件系统远程调用在不同进程中运行的软件是很常见的,这些进程可能在网络上的不同机器上运行。
内存调用和远程调用之间的一大区别是远程调用可能会失败,或者挂起而没有响应,直到达到某个超时限制。
更糟糕的是,如果我们有很多呼叫者呼叫一个无响应的供应商,那么我们可能会耗尽关键资源,导致多个系统发生级联故障。
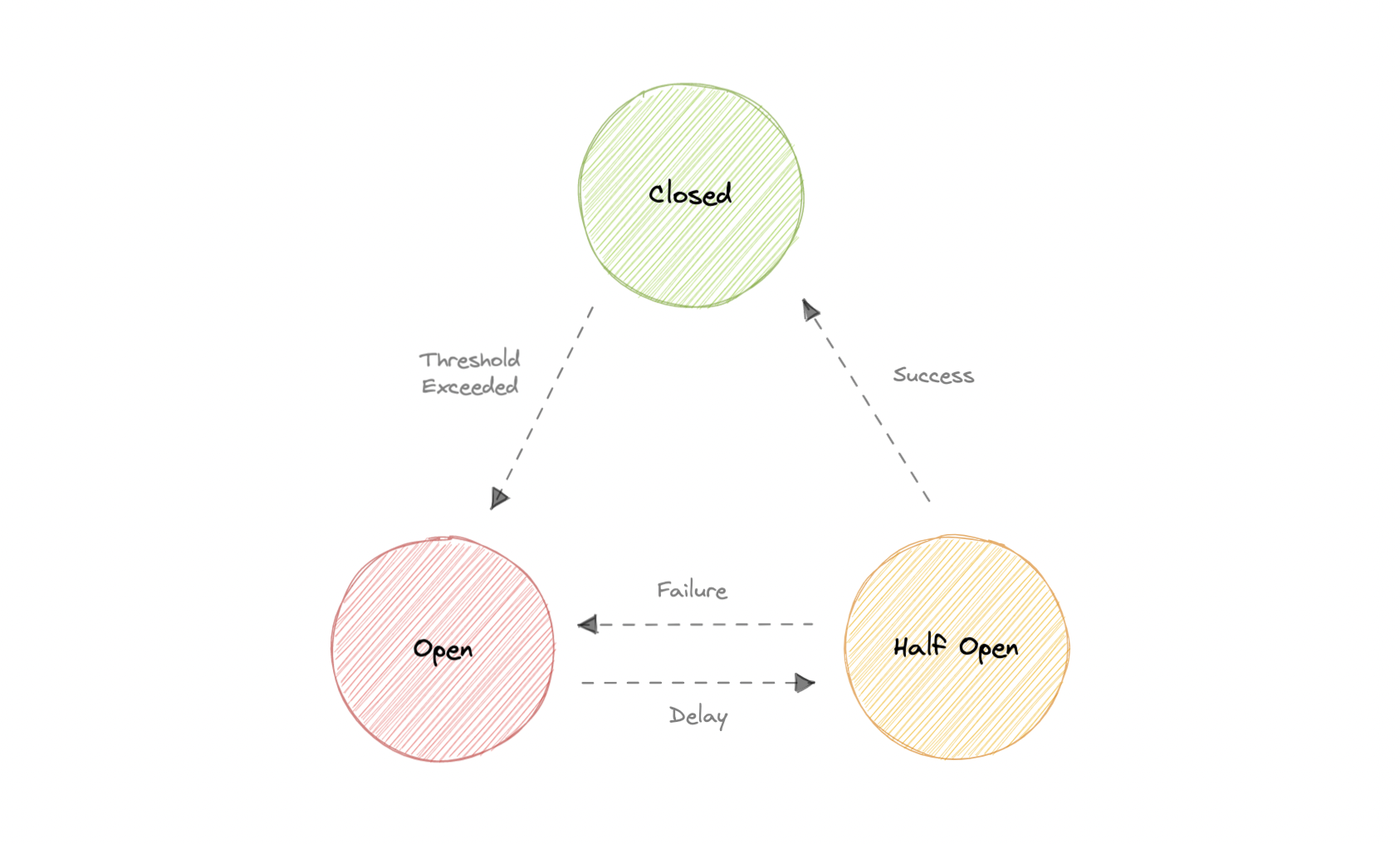
熔断器状态
-
Closed关闭当一切正常时,断路器保持关闭状态,所有请求都正常传递到服务。 如果故障次数增加超过阈值,断路器将跳闸并进入断开状态。
-
Open打开在此状态下,断路器会立即返回错误,甚至无需调用服务。 经过一定的超时时间后,断路器进入半开状态。 通常,它将有一个监控系统,其中将指定超时。
-
Half-open半开在这种状态下,断路器允许来自服务的有限数量的请求通过并调用操作。 如果请求成功,断路器将进入关闭状态。 但是,如果请求继续失败,则它会返回到打开状态。
速率限制 Rate Limiting
速率限制是指防止操作的频率超过定义的限制。
在大型系统中,速率限制通常用于保护底层服务和资源。
限速一般作为分布式系统中的一种防御机制,使共享资源保持可用性。
它还通过限制在给定时间段内可以到达我们 API 的请求数量来保护我们的 API 免受意外或恶意过度使用。
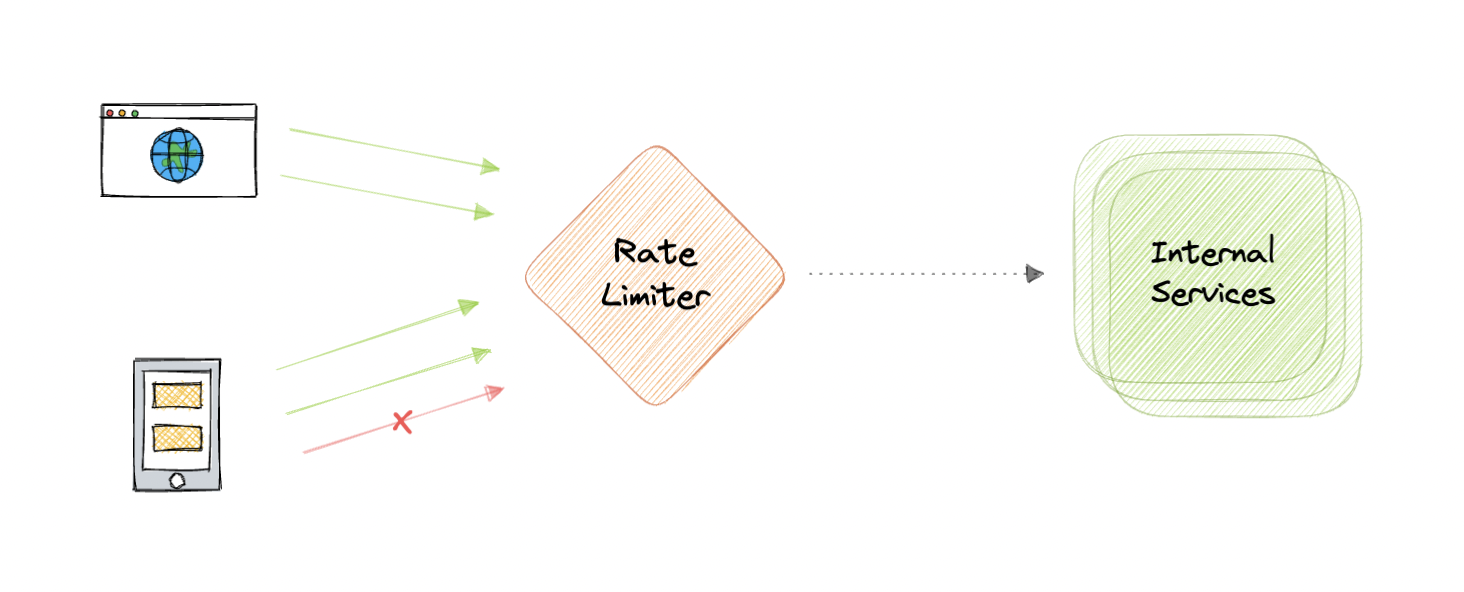
为什么需要速率限制?
速率限制是任何大型系统的一个非常重要的部分,它可以用来完成以下任务
避免因拒绝服务 (DoS) 攻击而导致资源匮乏。
速率限制通过对资源的自动缩放设置虚拟上限来帮助控制运营成本,如果不对其进行监控,可能会导致费用呈指数增长。
速率限制可用作防御或缓解某些常见攻击。
对于处理大量数据的 API,可以使用速率限制来控制该数据的流动。
API 速率限制有多种算法
- 漏水桶
Leaky Bucket
漏桶是一种算法,它提供了一种简单、直观的方法来通过队列进行速率限制。
注册请求时,系统将其附加到队列的末尾。
对队列中第一项的处理以固定间隔或先进先出 (FIFO) 发生。
如果队列已满,则丢弃(或泄漏)其他请求。
-
令牌桶
Token Bucket当请求进来时,必须从桶中取出一个令牌并进行处理。
如果桶中没有可用的令牌,请求将被拒绝,请求者必须稍后重试。
因此,令牌桶会在一定时间后刷新。
-
固定窗口
Fixed Window
系统使用 n 秒的窗口大小来跟踪固定窗口算法速率。
每个传入请求都会增加窗口的计数器。
如果计数器超过阈值,它会丢弃请求。
- 滑动日志
Sliding Log
滑动日志速率限制涉及跟踪每个请求的时间戳日志。
系统将这些日志存储在按时间排序的哈希集或表中。
它还会丢弃时间戳超出阈值的日志。
当有新的请求进来时,我们计算日志的总和来确定请求率。
如果请求将超过阈值速率,则将被保留。
- 滑动窗口
Sliding Window
滑动窗口是一种混合方法,它结合了固定窗口算法的低处理成本和滑动日志改进的边界条件。
与固定窗口算法一样,我们为每个固定窗口跟踪一个计数器。
接下来,我们根据当前时间戳计算前一个窗口请求率的加权值,以平滑突发流量。
分布式系统中的速率限制
Rate Limiting in Distributed Systems
涉及分布式系统时,速率限制变得复杂。
分布式系统中速率限制带来的两个广泛问题是
- 不一致
Inconsistencies
当使用多个节点的集群时,我们可能需要执行全局速率限制策略。
因为如果每个节点都跟踪其速率限制,则消费者在向不同节点发送请求时可能会超过全局速率限制。
节点数量越多,用户越有可能超过全局限制。
解决此问题的最简单方法是在我们的负载均衡器中使用粘性会话,以便每个消费者都被发送到一个节点,但这会导致缺乏容错和扩展问题。
另一种方法可能是使用像 Redis 这样的集中式数据存储,但这会增加延迟并导致竞争条件。
- 竞争条件
Race Conditions
当我们使用天真的“get-then-set”方法时会发生此问题,在该方法中我们检索当前速率限制计数器,递增它,然后将其推回数据存储区。
该模型的问题在于,在执行读取-增量-存储的完整周期所需的时间内可能会出现额外的请求,每个请求都试图用无效的(较低的)计数器值存储增量计数器。
这允许消费者发送大量请求以绕过速率限制控制。
避免此问题的一种方法是在密钥周围使用某种分布式锁定机制,以防止任何其他进程访问或写入计数器。
尽管锁将成为一个重要的瓶颈并且无法很好地扩展。
更好的方法可能是使用“set-then-get”方法,允许我们快速递增和检查计数器值,而不会让原子操作妨碍。
服务发现 Service Discovery
服务发现是在计算机网络中检测服务。
服务发现协议(Service Discovery Protocol,SDP)是一种网络标准,通过识别资源来完成对网络的检测。
为什么需要服务发现?
在单体应用程序中,服务通过语言级方法或过程调用相互调用。
然而,现代基于微服务的应用程序通常在虚拟化或容器化环境中运行,在这些环境中,服务实例的数量及其位置会动态变化。
因此,我们需要一种机制,使服务的客户端能够向一组动态变化的临时服务实例发出请求
两种主要的服务发现模式
Client-side discovery客户端发现
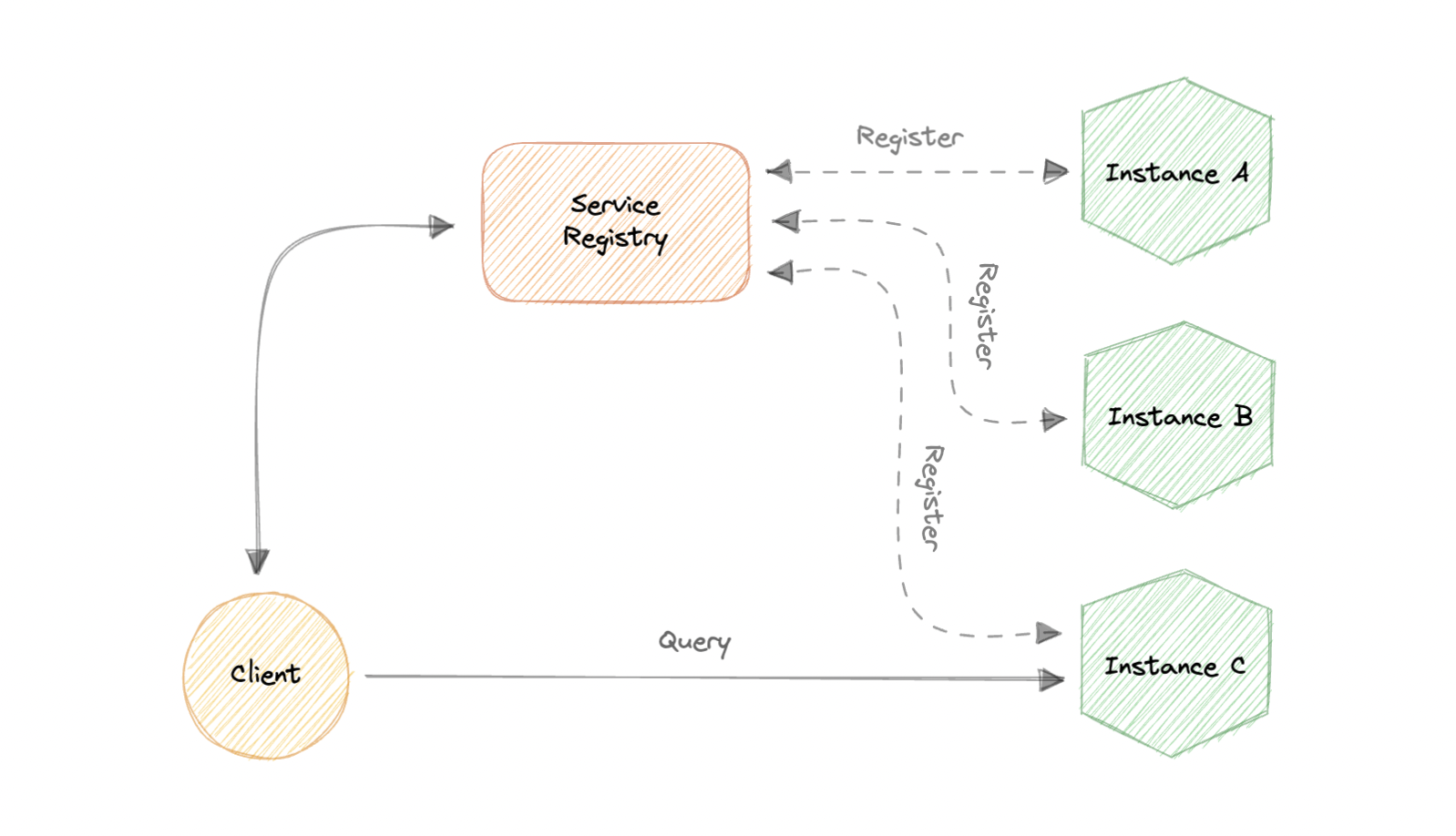
在这种方法中,客户端通过查询服务注册表来获取另一个服务的位置
该服务注册表负责管理和存储所有服务的网络位置
Server-side discovery服务器端发现
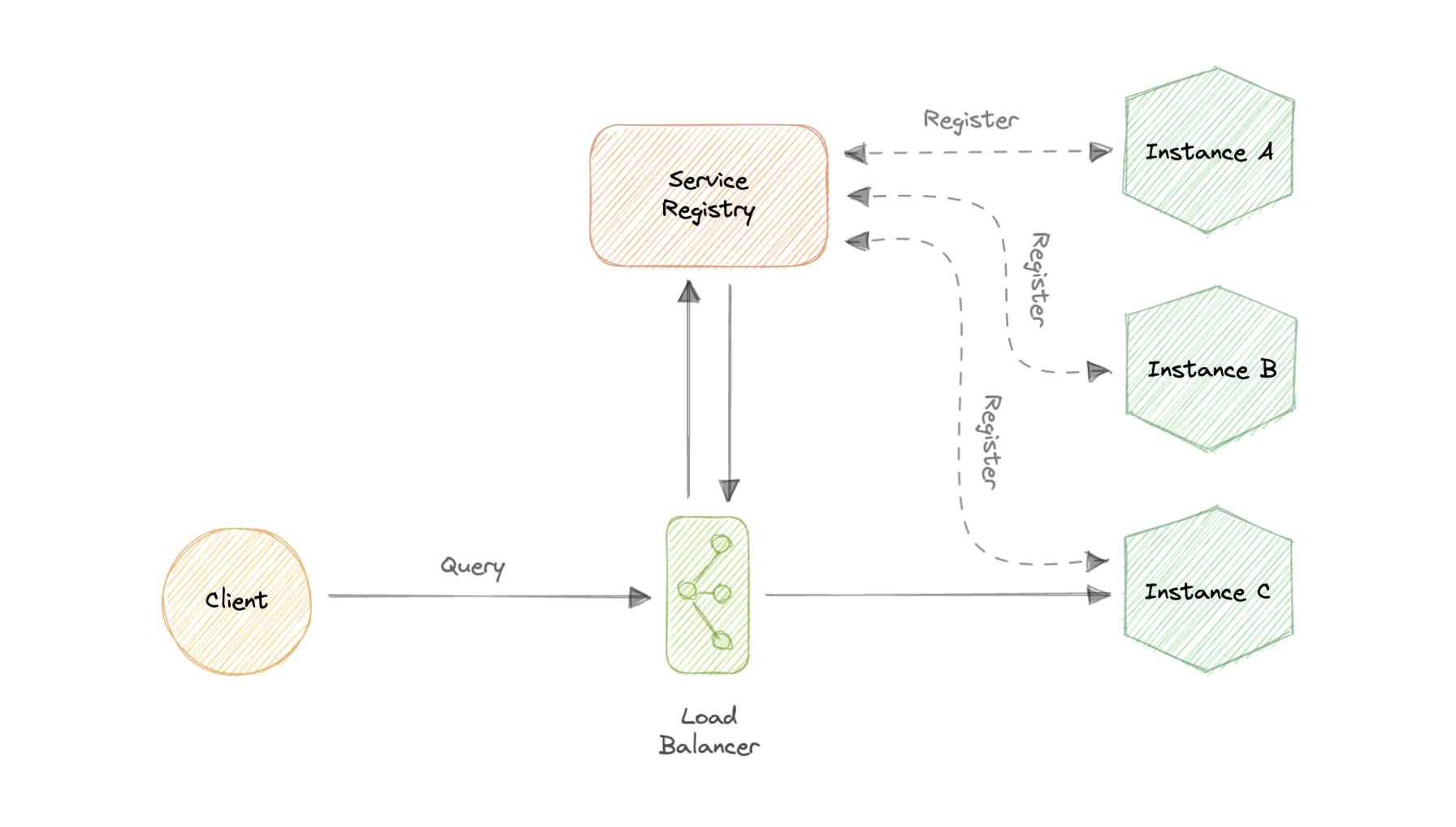
在这种方法中,我们使用一个中间组件,例如负载均衡器。
客户端通过负载均衡器向服务发出请求,然后负载均衡器将请求转发到可用的服务实例
服务注册
Service Registration
我们还需要一种获取服务信息的方法,通常称为服务注册。
两种可能的服务注册方法:
- 自助注册
Self-Registration
使用自注册模型时,服务实例负责在服务注册表中注册和注销自己。 此外,如有必要,服务实例会发送心跳请求以保持其注册活动。
- 第三方注册
Third-party Registration
注册表通过轮询部署环境或订阅事件来跟踪运行实例的变化。 当它检测到新的可用服务实例时,它会将其记录在其数据库中。 服务注册中心还注销终止的服务实例。
服务网格
Service mesh
服务到服务的通信在分布式应用程序中是必不可少的,但是随着服务数量的增长,在应用程序集群内和跨应用程序集群路由这种通信变得越来越复杂。
服务网格支持各个服务之间的托管、可观察和安全通信。 它使用服务发现协议来检测服务。
Istio 和 Envoy 是一些最常用的服务网格技术
常用的服务发现基础设施工具
etcd
Consul
Apache Thrift
Apache Zookeeper
服务水平协议 SLA, SLO, SLI
SLA、SLO 和 SLI 允许公司定义、跟踪和监控为其用户做出的服务承诺。
SLA、SLO 和 SLI 应共同帮助团队获得更多用户对其服务的信任,同时更加强调持续改进事件管理和响应流程
SLA
SLA 或服务级别协议是公司与其给定服务的用户之间达成的协议。
SLA 定义了公司就特定指标(例如服务可用性)向用户做出的不同承诺。
SLA 通常由公司的业务或法律团队编写。
SLO
SLO 或服务级别目标是公司就事件响应或正常运行时间等特定指标向用户做出的承诺。
SLO 作为包含在完整用户协议中的单独承诺存在于 SLA 中。
SLO 是服务必须满足的特定目标,以符合 SLA。
SLO 应始终简单、明确定义且易于衡量,以确定目标是否实现。
SLI
SLI 或服务级别指标是用于确定是否满足 SLO 的关键指标。
它是 SLO 中描述的指标的测量值。
为了始终遵守 SLA,SLI 的值必须始终达到或超过 SLO 确定的值。
灾难恢复 (DR) Disaster recovery
灾难恢复 (DR) 是在发生自然灾害、网络攻击甚至业务中断等事件后重新获得基础设施访问权限和功能的过程。
灾难恢复依赖于在不受灾难影响的场外位置复制数据和计算机处理。
当服务器因灾难而停机时,企业需要从备份数据的第二个位置恢复丢失的数据。 理想情况下,组织也可以将其计算机处理转移到该远程位置,以便继续运营。
在系统设计面试中,灾难恢复通常不会被积极讨论,但对这个话题有一些基本的了解是很重要的。
您可以从 AWS Well-Architected Framework 了解更多关于灾难恢复的信息。
灾难恢复好处
最大限度地减少中断和停机时间
限制损害赔偿
快速恢复
更好的客户保留
灾难恢复相关的重要术语

RTO
恢复时间目标 (RTO) 是服务中断和服务恢复之间的最大可接受延迟。
这决定了当服务不可用时什么被认为是可接受的时间窗口。
RPO
恢复点目标 (RPO) 是自上一个数据恢复点以来的最长可接受时间量。
这决定了在最后一个恢复点和服务中断之间什么是可接受的数据丢失。
灾难恢复 (DR) 策略
- 备份
Back-up
这是最简单的灾难恢复类型,涉及将数据存储在异地或可移动驱动器上。
- 冷站
Cold Site
在这种类型的灾难恢复中,组织在第二个站点设置基本的基础设施。
- 热点站点
Hot site
热站点始终维护最新的数据副本。 热站点的设置非常耗时,而且比冷站点更昂贵,但它们大大减少了停机时间
虚拟机 (VM) 和容器 Virtual Machines (VMs) and Containers
虚拟机 (VM)
虚拟机 (VM) 是一种虚拟环境,其功能类似于在物理硬件系统上创建的具有自己的 CPU、内存、网络接口和存储的虚拟计算机系统。
称为管理程序 Hypervisor将机器的资源与硬件分开,并适当地配置它们,以便 VM 使用它们。
VM 与系统的其余部分隔离,并且多个 VM 可以存在于单个硬件(如服务器)上。 它们可以根据需要在主机服务器之间移动或更有效地使用资源。
Hypervisor管理程序
Hypervisor 有时称为虚拟机监视器 (VMM),将操作系统和资源与虚拟机隔离开来,并支持创建和管理这些 VM。
管理程序将 CPU、内存和存储等资源视为资源池,可以在现有来宾或新虚拟机之间轻松重新分配。
- 为什么要使用虚拟机?
服务器整合是使用 VM 的首要原因。
大多数操作系统和应用程序部署只使用少量可用的物理资源。 通过虚拟化我们的服务器,我们可以将许多虚拟服务器放置到每个物理服务器上,以提高硬件利用率。 这使我们无需购买额外的物理资源
VM 提供了一个与系统其余部分隔离的环境,因此 VM 内运行的任何内容都不会干扰主机硬件上运行的任何其他内容。
由于 VM 是独立的,因此它们是测试新应用程序或设置生产环境的不错选择。 我们还可以运行一个单一用途的 VM 来支持特定的用例。
容器
Containers
容器是一个标准的软件单元,它将代码及其所有依赖项(例如特定版本的运行时和库)打包在一起,以便应用程序能够快速可靠地从一个计算环境运行到另一个计算环境。
容器提供了一种逻辑打包机制,应用程序可以从它们实际运行的环境中抽象出来。
这种解耦使得基于容器的应用程序可以轻松一致地部署,而不管目标环境如何。
-
为什么需要容器?
职责分离
容器化提供了明确的职责分离,因为开发人员专注于应用程序逻辑和依赖关系, 而运营团队可以专注于部署和管理。工作负载可移植性
容器几乎可以在任何地方运行,大大简化了开发和部署。应用隔离
容器在操作系统级别虚拟化 CPU、内存、存储和网络资源,为开发人员提供在逻辑上与其他应用程序隔离的操作系统视图。敏捷开发
容器允许开发人员通过避免对依赖性和环境的担忧来更快地移动。高效运营
容器是轻量级的,允许我们只使用我们需要的计算资源。
Virtualization vs Containerization虚拟化与容器化
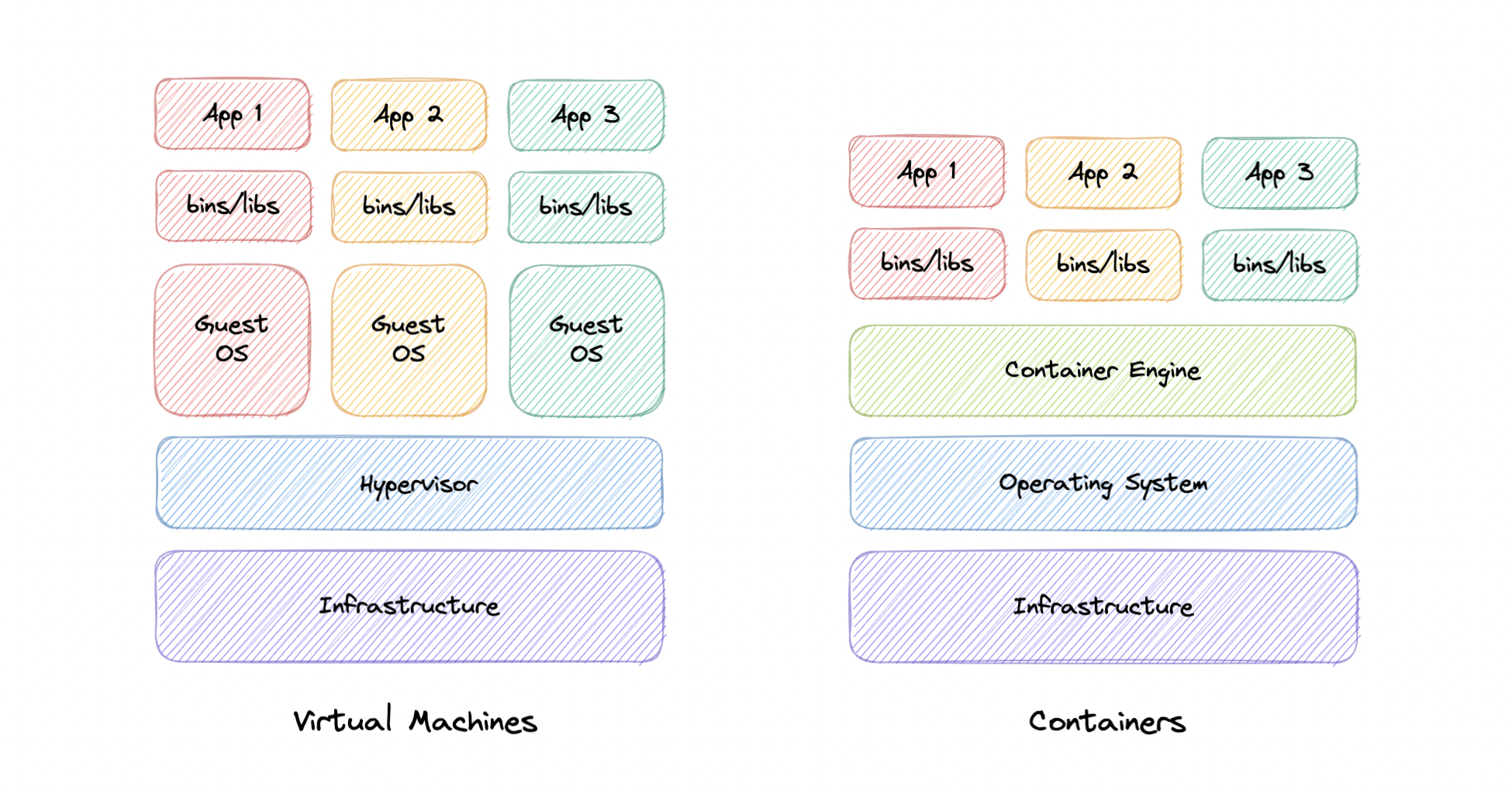
在传统虚拟化中,虚拟机管理程序虚拟化物理硬件。
结果是每个虚拟机都包含 一个客户操作系统、一个操作系统运行所需的硬件的虚拟副本,以及一个应用程序及其关联的库和依赖项。
容器不是虚拟化底层硬件,而是虚拟化操作系统,因此每个容器仅包含应用程序及其依赖项,从而使它们比 VM 轻量级得多。
容器还共享操作系统内核并使用 VM 所需内存的一小部分。
OAuth 2.0 和 OpenID 连接 (OIDC)
OAuth 2.0
OAuth 2.0 代表开放授权,是一种标准,旨在代表用户提供对资源的同意访问,而无需共享用户的凭据`。
OAuth 2.0 是一种授权协议而不是身份验证协议,它主要被设计为一种授予对一组资源(例如,远程 API 或用户数据)的访问权限的方式
-
OAuth 2.0协议定义了以下实体资源所有者 Resource Owner:拥有受保护资源并可以授予访问权限的用户或系统。客户端 Client:客户端是需要访问受保护资源的系统。授权服务器 Authorization Server:该服务器接收来自客户端的访问令牌请求,并在资源所有者成功验证和同意后发出这些请求。资源服务器 Resource Server:保护用户资源并接收来自客户端的访问请求的服务器。 它接受并验证来自客户端的访问令牌并返回适当的资源。范围 Scopes:它们用于准确指定可以授予资源访问权限的原因。 可接受的范围值以及它们与哪些资源相关,取决于资源服务器。Access Token:代表最终用户访问资源的授权的一段数据。
- OAuth 2.0 的工作原理
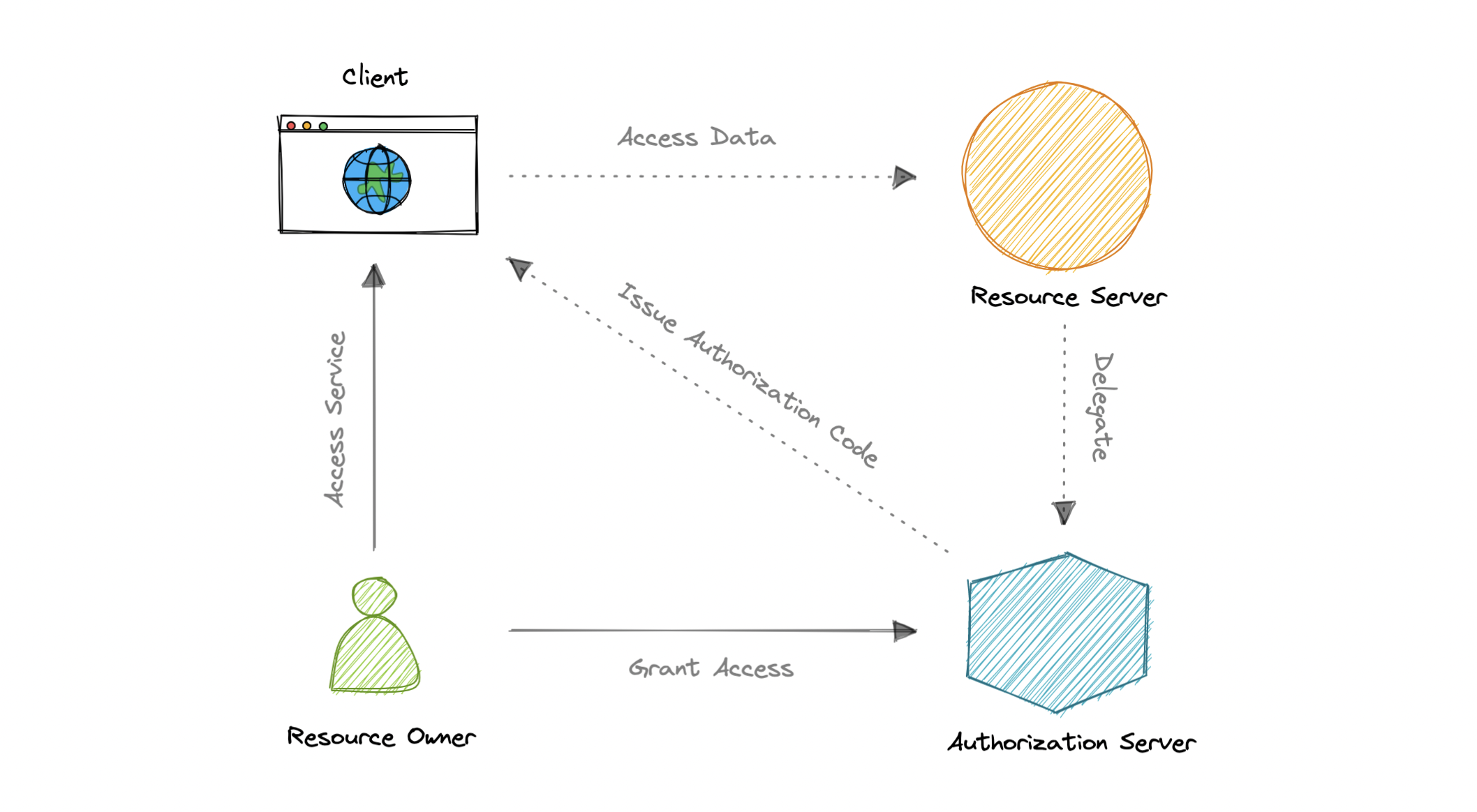
1 客户端向授权服务器请求授权,提供客户端 ID 和密码作为标识。
它还提供范围和端点 URI 以发送访问令牌或授权代码。
2 授权服务器对客户端进行身份验证并验证请求的范围是否被允许。
3 资源所有者与授权服务器交互以授予访问权限。
4 授权服务器使用授权码或访问令牌重定向回客户端,具体取决于授权类型。 也可以返回刷新令牌。
5 使用访问令牌,客户端可以向资源服务器请求访问资源。
-
OAuth 2.0最常见的缺点:缺乏内置的安全功能。
没有标准的实现。
没有通用的范围集。
OpenID 连接
OAuth 2.0 专为授权而设计,用于将数据和功能的访问权限从一个应用程序授予另一个应用程序。
OpenID Connect (OIDC) 是一个位于 OAuth 2.0 之上的薄层,它添加了有关登录人员的登录和个人资料信息
当授权服务器支持 OIDC 时,它有时被称为身份提供者 (IdP),因为它向客户端提供有关资源所有者的信息。
OpenID Connect 相对较新,因此与 OAuth 相比,最佳实践的采用率和行业实施率较低。
-
OpenID Connect (OIDC)协议定义了以下实体:依赖方:当前应用程序。
OpenID Provider:这本质上是一种中间服务,向依赖方提供一次性代码。
令牌端点:接受一次性代码 (OTC) 并提供一小时有效访问代码的 Web 服务器。 OIDC 和 OAuth 2.0 之间的主要区别在于令牌是使用 JSON Web 令牌 (JWT) 提供的。
UserInfo 端点:依赖方与此端点通信,提供安全令牌并接收有关最终用户的信息
OAuth 2.0 和 OIDC 都易于实现,并且都是基于 JSON 的,大多数 Web 和移动应用程序都支持它。
但是,OpenID Connect (OIDC) 规范比基本 OAuth 规范更严格。
单点登录 (SSO) Single Sign-On
单点登录 (SSO) 是一种身份验证过程,在该过程中,用户仅使用一组登录凭据即可访问多个应用程序或网站。
这避免了用户分别登录不同应用程序的需要。
用户凭据和其他识别信息由称为身份提供者 (IdP) 的集中式系统存储和管理。
身份提供者是一个受信任的系统,可以提供对其他网站和应用程序的访问。
基于单点登录 (SSO) 的身份验证系统通常用于员工需要访问其组织的多个应用程序的企业环境中
单点登录 (SSO) 的一些关键组件
-
身份提供者 (IdP)
Identity Provider (IdP)用户身份信息由称为身份提供者 (IdP) 的集中式系统存储和管理。
身份提供者对用户进行身份验证并提供对服务提供者的访问。
身份提供者可以通过验证用户名和密码或通过验证由单独的身份提供者提供的关于用户身份的断言来直接验证用户。
身份提供者处理用户身份的管理,以便将服务提供者从这一责任中解放出来。
-
服务提供者
Service Provider服务提供商向最终用户提供服务。
他们依靠身份提供者来断言用户的身份,并且通常有关用户的某些属性由身份提供者管理。
服务提供商还可以为用户维护一个本地帐户以及他们的服务所特有的属性。
-
身份代理
Identity Broker身份代理充当中介,将多个服务提供者与各种不同的身份提供者连接起来。
使用 Identity Broker,我们可以在任何应用程序上执行单点登录,而无需遵循它所遵循的协议。
-
SAML
Security Assertion Markup Languag安全断言标记语言安全断言标记语言是一种开放标准,允许客户端在不同系统之间共享有关身份、身份验证和权限的安全信息。
SAML 是通过可扩展标记语言 (XML) 标准实现的,用于共享数据。
SAML 专门支持身份联合,使身份提供者 (IdP) 可以无缝、安全地将经过身份验证的身份及其属性传递给服务提供者。
单点登录的工作原理
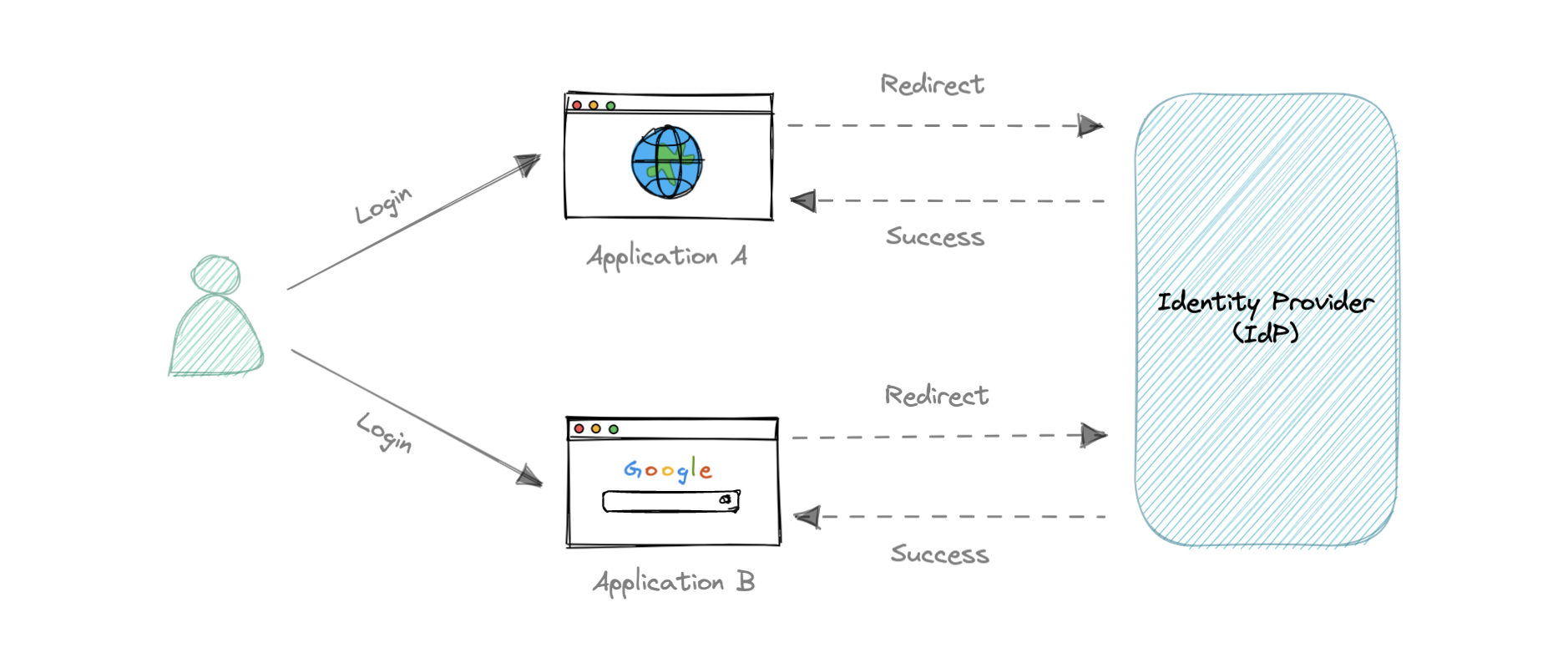
1 用户从他们想要的应用程序中请求资源。
2 该应用程序将用户重定向到身份提供者 (IdP) 以进行身份验证。
3 用户使用他们的凭据(通常是用户名和密码)登录。
4 身份提供者 (IdP) 将单点登录响应发送回客户端应用程序。
5 应用程序授予用户访问权限
SAML与OAuth 2.0和OpenID Connect (OIDC)
SAML 使用 XML 来传递消息,而 OAuth 和 OIDC 使用 JSON。
OAuth 提供更简单的体验,而 SAML 则面向企业安全。
OAuth 和 OIDC 广泛使用 RESTful 通信,这就是移动和现代 Web 应用程序发现 OAuth 和 OIDC 为用户带来更好体验的原因。
SAML 在浏览器中放置一个会话 cookie,允许用户访问某些网页。 这非常适合短期工作负载。
OIDC 对开发人员友好且易于实施,从而拓宽了可能实施的用例。 它可以通过所有常见编程语言的免费库从头开始非常快速地实现。
SAML 的安装和维护可能很复杂,只有企业规模的公司才能处理好。
OpenID Connect 本质上是 OAuth 框架之上的一个层。
因此,它可以提供一个内置的权限层,要求用户同意服务提供商可能访问的内容。
尽管 SAML 也能够允许同意流,但它是通过开发人员执行的硬编码实现的,而不是作为其协议的一部分
优缺点
优点
易于使用,因为用户只需要记住一组凭据。
无需经过冗长的授权过程即可轻松访问。
强制执行安全性和合规性以保护敏感数据。
通过减少 IT 支持成本和管理时间来简化管理。
缺点
单一密码漏洞,如果主 SSO 密码被泄露,所有受支持的应用程序都会被泄露。
使用单点登录的身份验证过程比传统身份验证慢,因为每个应用程序都必须请求 SSO 提供商进行验证。
常用的身份提供者 (IdP):
Okta
Google
Auth0
OneLogin
SSL、TLS、mTLS 通信安全协议
SSL
SSL 代表安全套接字层,它指的是一种用于加密和保护互联网上发生的通信的协议。
它于 1995 年首次开发,但后来被弃用,取而代之的是 TLS(传输层安全性) Transport Layer Security。
大多数主要的证书提供商仍然将证书称为 SSL 证书,命名约定仍然存在。
-
为什么
SSL如此重要?最初,网络上的数据以明文形式传输,任何人如果截获消息都可以阅读。
创建 SSL 是为了解决此问题并保护用户隐私。
通过加密用户和 Web 服务器之间的任何数据,SSL 还通过防止攻击者篡改传输中的数据来阻止某些类型的网络攻击。
TLS
传输层安全性或 TLS 是一种广泛采用的安全协议,旨在促进互联网通信的隐私和数据安全。
TLS 从以前称为安全套接字层 (SSL) 的加密协议演变而来。
TLS 的一个主要用例是加密 Web 应用程序和服务器之间的通信。
-
TLS 协议完成的工作包括三个主要组成部分:加密 Encryption:隐藏从第三方传输的数据。
身份验证 Authentication:确保交换信息的各方与其声称的身份相符。
完整性 Integrity:验证数据没有被伪造或篡改。
mTLS
Mutual TLS 或 mTLS 是一种相互身份验证的方法。
mTLS 通过验证他们都拥有正确的私钥来确保网络连接每一端的各方都是他们声称的人。
他们各自的 TLS 证书中的信息提供了额外的验证。
-
为什么使用
mTLS?mTLS 有助于确保流量在客户端和服务器之间的双向安全和可信。
这为登录到组织网络或应用程序的用户提供了额外的安全层。
它还会验证与不遵循登录过程的客户端设备的连接,例如物联网 (IoT) 设备。
如今,mTLS 通常被零信任安全模型中的微服务或分布式系统用于相互验证。
